
Released September 8th, 2022.
New Features
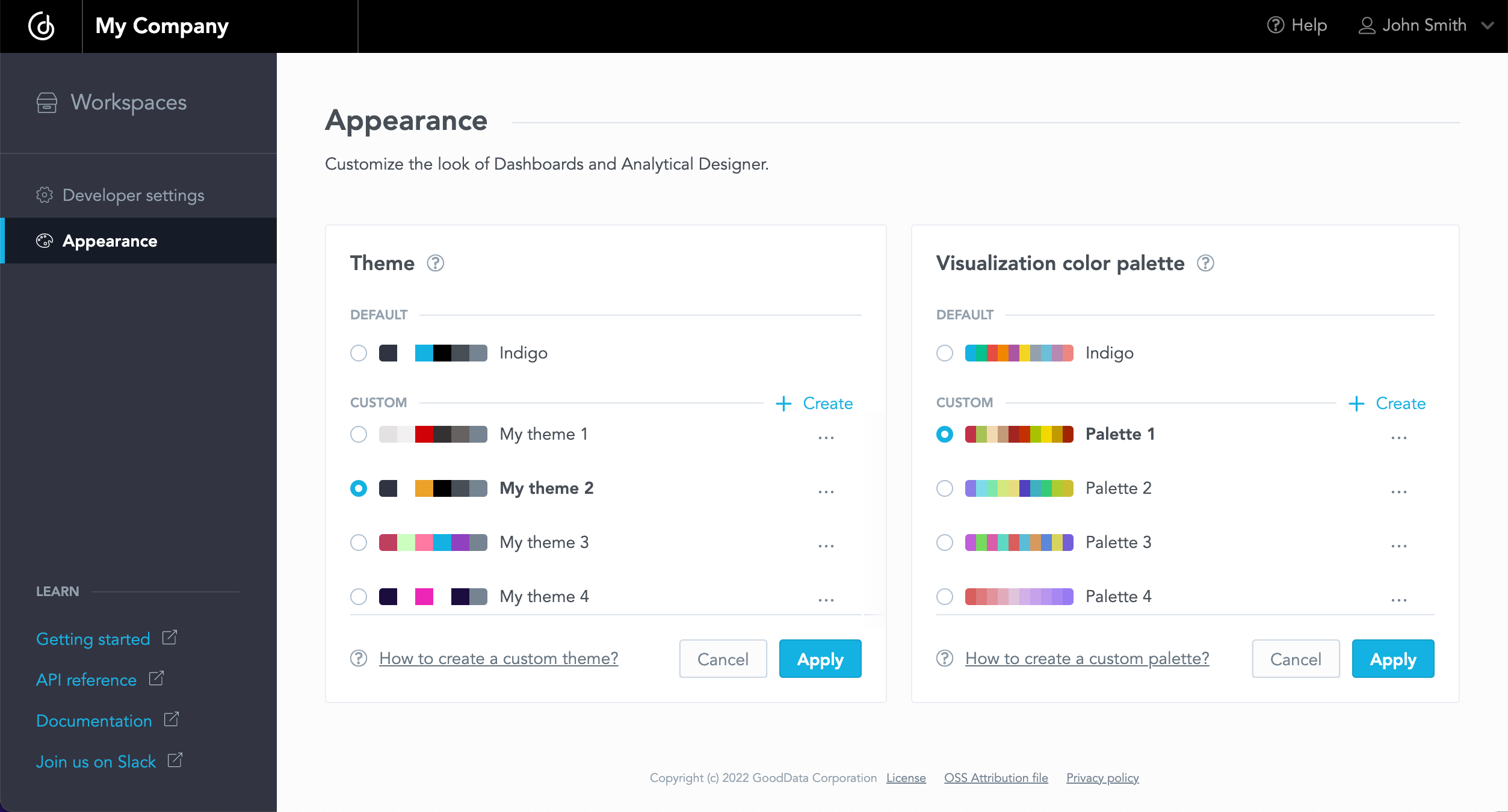
Customizable Appearance
You can now customize the color schemes of your GoodData.CN deployment using the newly added Appearance settings. You can create custom themes for your dashboard and analytical designer, as well as color palettes for your visualization.
The color schemes are applied to the organization as a whole by default, but you can use different themes for different workspaces via API.
Please note that this feature is currently not available in GoodData.CN Community Edition.
Learn more:
Customize Appearance
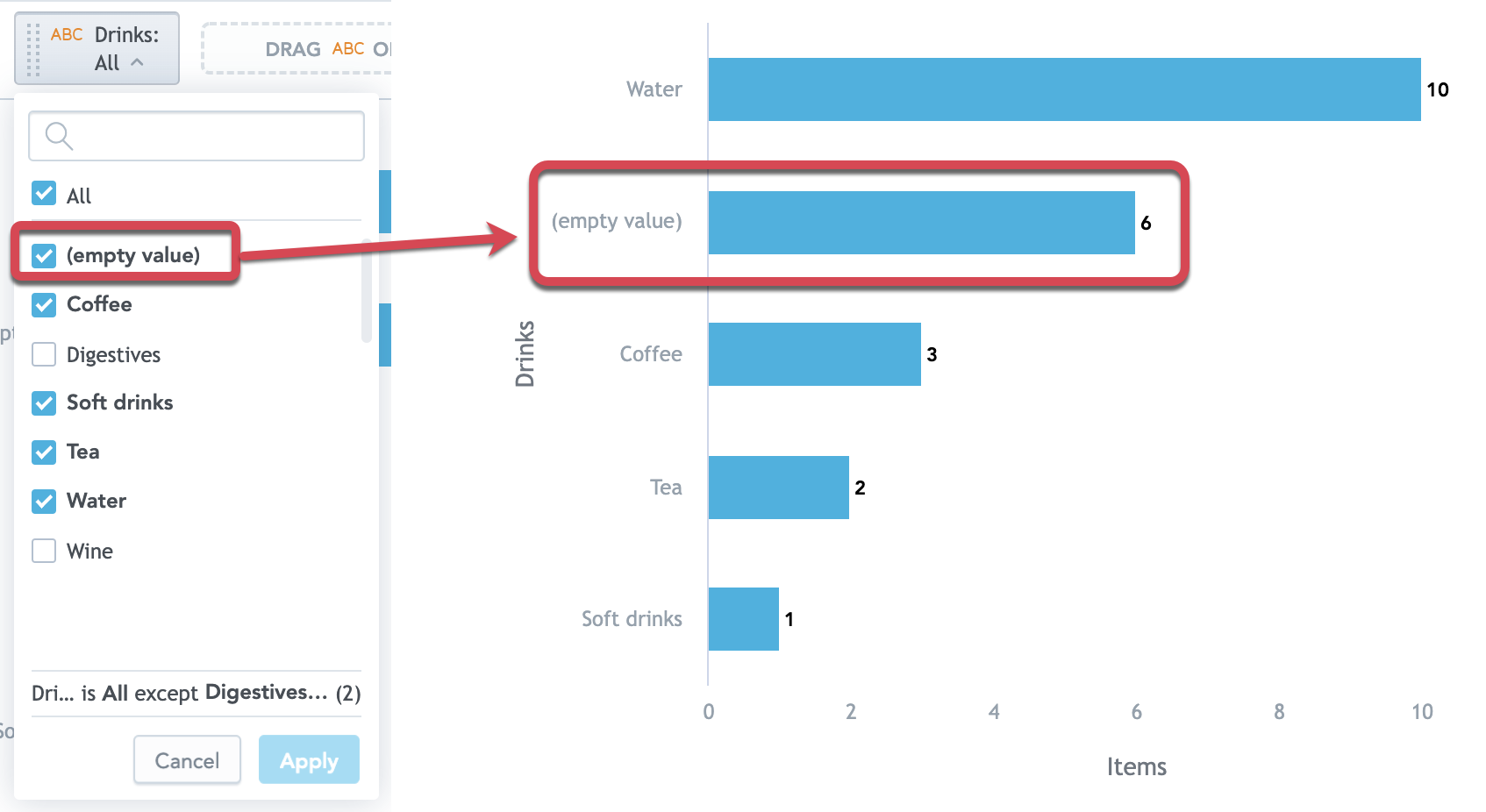
Support for Filtering of Empty Attribute Values
In GoodData.CN, attribute filters now support the empty (NULL) values.
You can now include or exclude these empty values from your filters in MAQL definitions or directly in Analytical Designer or Dashboards.
Learn more:
Filter Visualizations by Attributes and Dates
Relational Operators
Support for Time Zones
You can now configure time zones for your whole organization, or individual workspaces or users via API.
If not specifically configured, users inherit time zone settings from their workspace; workspaces inherit the time zone settings from their parent workspace or organization.
With correct time zones, your users can always see relevant data when they filter to, for example, Today or Last hour.
Notes:
- If you use the
TIMESTAMPTZdata type and you are a current GoodData.CN user, scan your data sources again to detect the columns with the time zone information. - We recommend configuring the time zone for the organization or workspace, so that you always see relevant data (the default is
UTC)
Learn more:
Manage Time Zones
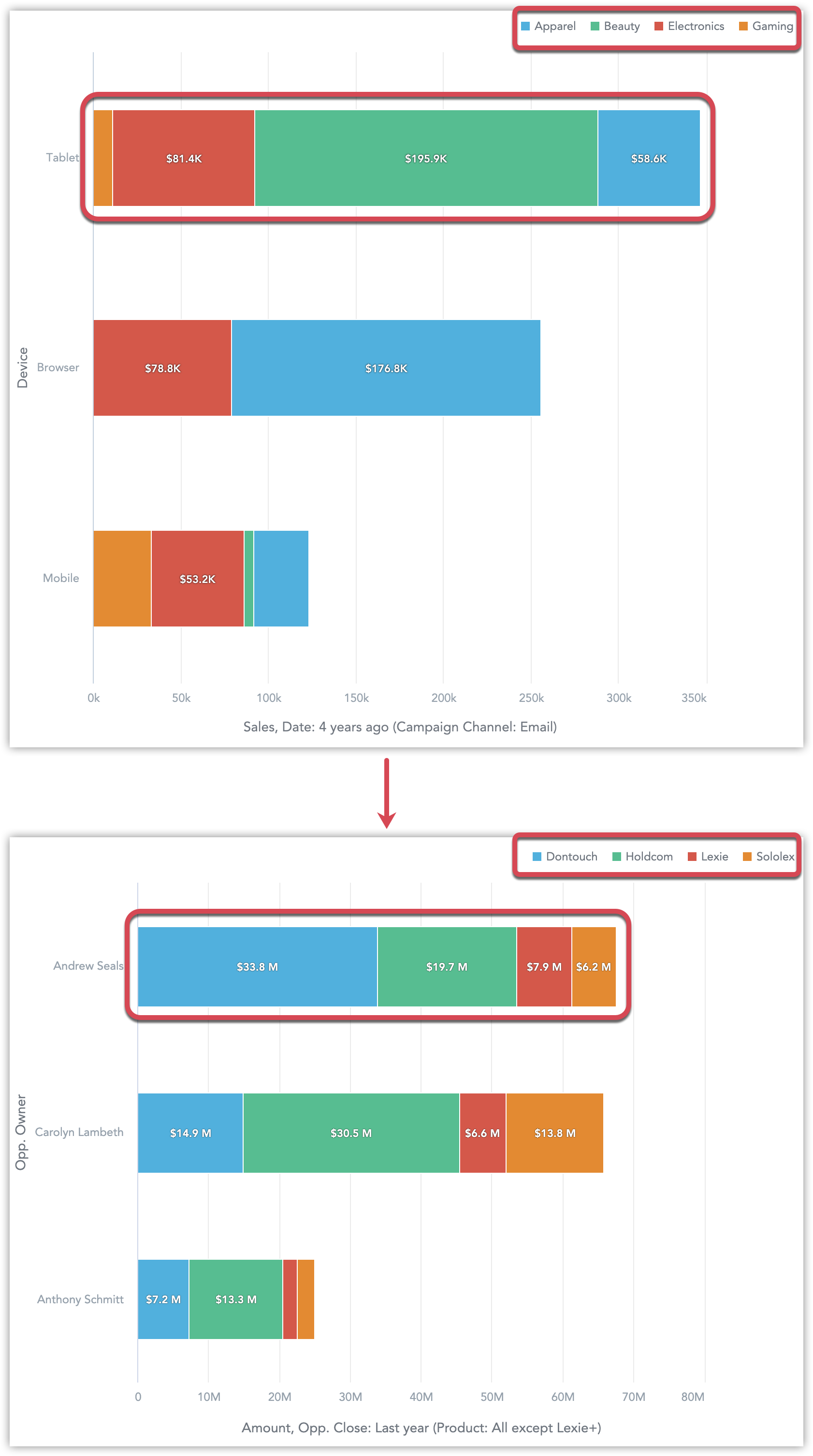
Order of Items in Stacked Charts
To improve the readability of charts with stacked items, we have reversed the order of the items displayed.
In bar charts, column charts, and stacked area charts, the order of the items now corresponds with the left-to-right order in the legend.
New Entitlements API
We have expanded the previously introduced API endpoint /actions/resolveEntitlements.
Organization administrators can now get information about the current number of used workspaces and users from in license.
We have also introduced a new API endpoint /actions/collectUsage that displays how many workspaces and users currently exist in your organization.
Learn more:
View Entitlements
View Usage
New API Filter Entity
You can now filter workspace entities using the origin=ALL|PARENTS|NATIVE filter to get only the workspace itself, or only its parent workspaces, or both.
Learn more:
Origin
Configurable CSP For Organizations
Control hostname restrictions for your GoodData deployment with Content Security Policy (CSP). Your organization's CSP directives can be configured using the new API endpoint /entities/cspDirectives.
Learn more:
Enable CSP for an Organization
End of Beta For Permissions
After months of testing we now consider permissions to be a fully tested feature and no longer in beta. Our thanks goes to all the early adopters.
Learn more:
Manage Permissions
Fixes and Updates
- You can now set a custom Timeout duration when connecting to Google BigQuery, allowing you to increase the duration past the 10 second default.
- We fixed an issue where queries that return large amounts of data, on the order of millions of rows, would fail due to cache memory issues.
-
GoodData.CN now uses Redshift driver version 2.1.0.9 and Snowflake driver version 3.13.21.
- GoodData.CN now uses Apache Pulsar 2.9.3. Please note that this will require you to update
customized-values-pulsar.yamlwhen upgrading to GoodData.CN 2.1, for more information, see Upgrade GoodData.CN to 2.1 below.
Get the Community Edition
Pull the GoodData.CN Community Edition to get started with the latest release:
docker pull gooddata/gooddata-cn-ce:2.1.0
Upgrade Guides
Upgrade GoodData.CN Community Edition to 2.1
Suppose you are using a docker volume to store metadata from your GoodData.CN CE container. Download a new version of the GoodData.CN CE docker image and start it with your volume. All your metadata is migrated automatically.
Upgrade GoodData.CN to 2.1
Preload updated Custom Resource Definition (CRD) for Organization resources. Due to the helm command limitation, it is impossible to update CRD automatically by Helm. Therefore it is necessary to update this CRD manually by following this procedure:
-
Download and extract gooddata-cn helm chart to an empty directory on local disk.
helm pull gooddata/gooddata-cn --version 2.1.0 --untar -
Update modified CRD in the cluster where the older GoodData.CN release is deployed:
kubectl apply -f gooddata-cn/crds/organization-crd.yaml -
You can clean local extracted helm chart
rm-r gooddata-cn -
The new version of Apache Pulsar in GoodData.CN 2.1 requires you update the
customized-values-pulsar.yaml. The following two lines need to be added to the Pulsar broker configuration:systemTopicEnabled: "true"
topicLevelPoliciesEnabled: "true"Note that you may need to restart the broker pod after making this change, or just uncomment the
restartPodsOnConfigMapChange: trueline.See Use Customized values.yaml for Pulsar that contains the updated version of
customized-values-pulsar.yamlwith these changes already integrated. - If you are using embedded PostgreSQL database, refer to the following Upgrade Postgresql-ha Helm Chart section for instructions on how to upgrade it.
- Perform a rescan of your data source with replace mode, to create an up-to-date version of the physical data model and to avoid any unwanted errors when regenerating the logical data model.
Upgrade Postgresql-ha Helm Chart
If you’re using external PostgreSQL database (when you deployed gooddata-cn helm chart with option deployPostgresHA: false), you can skip this step because it is not relevant for your deployment.
If you’re using embedded PostgreSQL database (with deployPostgresHA: true set in values.yaml), you will need to perform the following process to upgrade postgresql-ha helm chart from version 8.6.13 to 9.1.5:
Follow the steps in this article to upgrade your helm chart for GoodData.CN 2.1.0.