Hello all.
I would like to start a discussion about how you do or how would you do benchmarking in GoodData. I would like to provide my customers which are in the same business some comparison of some key metrics against aggregated data from all customers / industry standard.
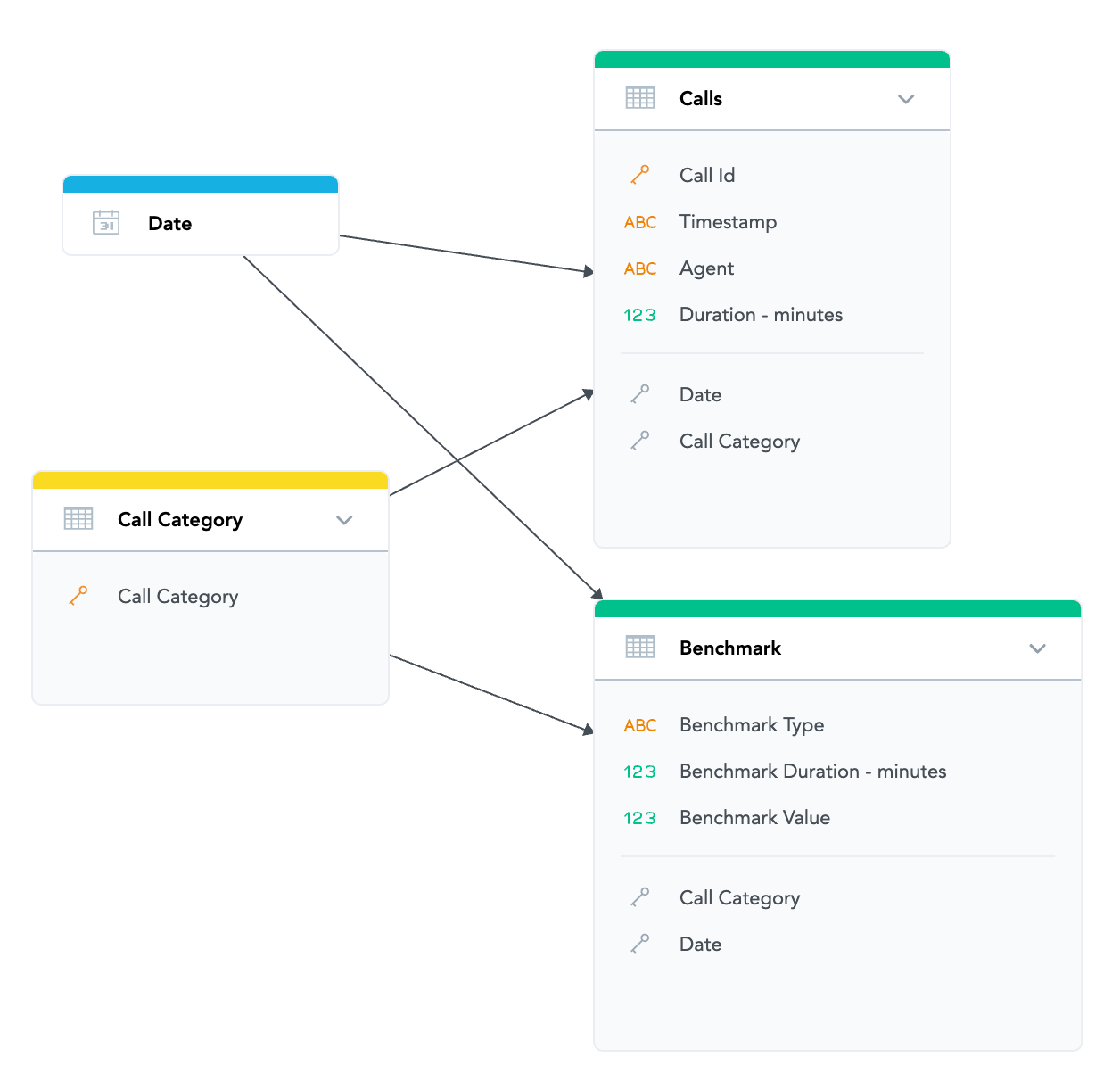
I was playing with a dummy model and data and it seems that something simple as second dataset with the aggregated data works well:
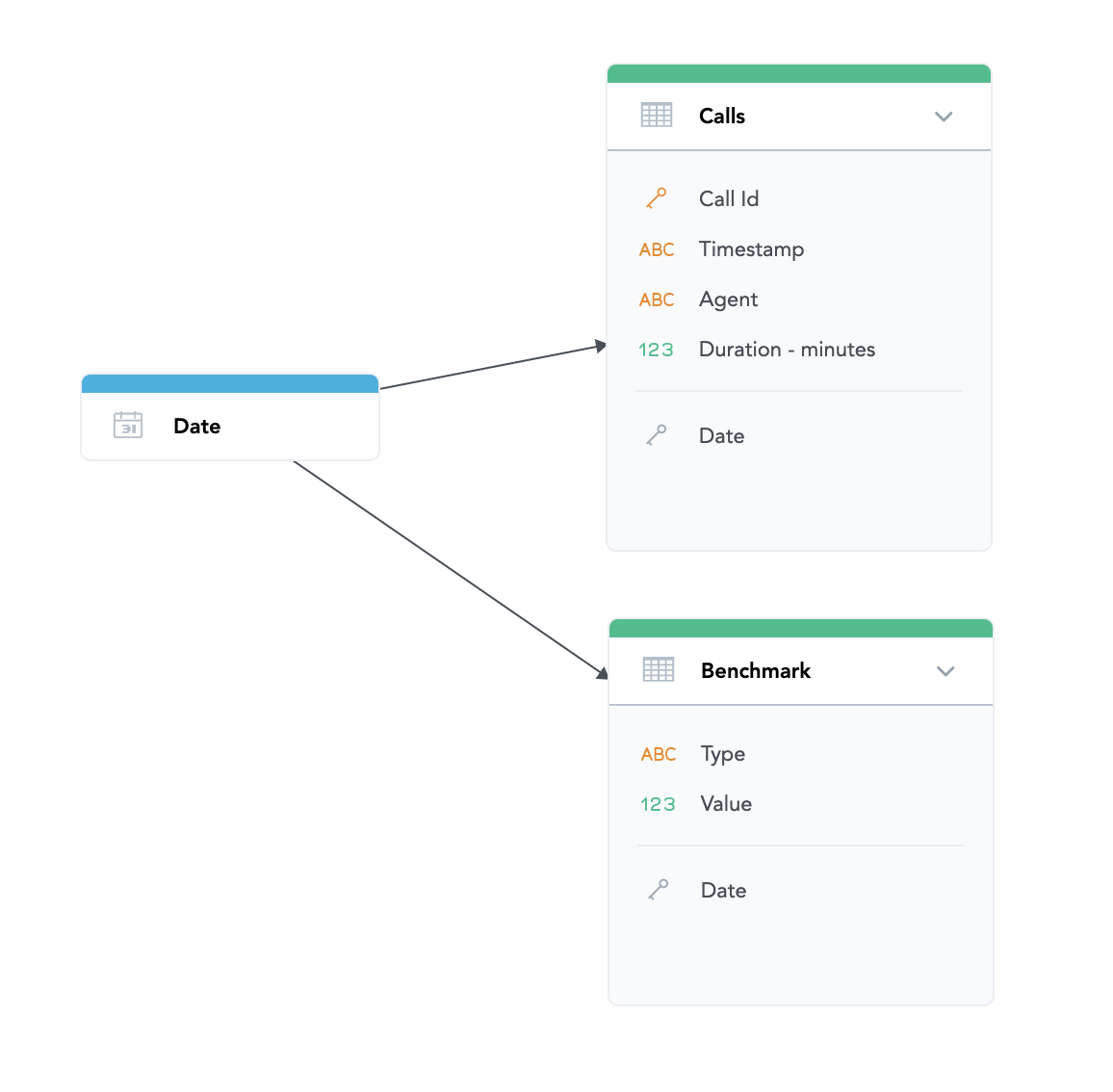
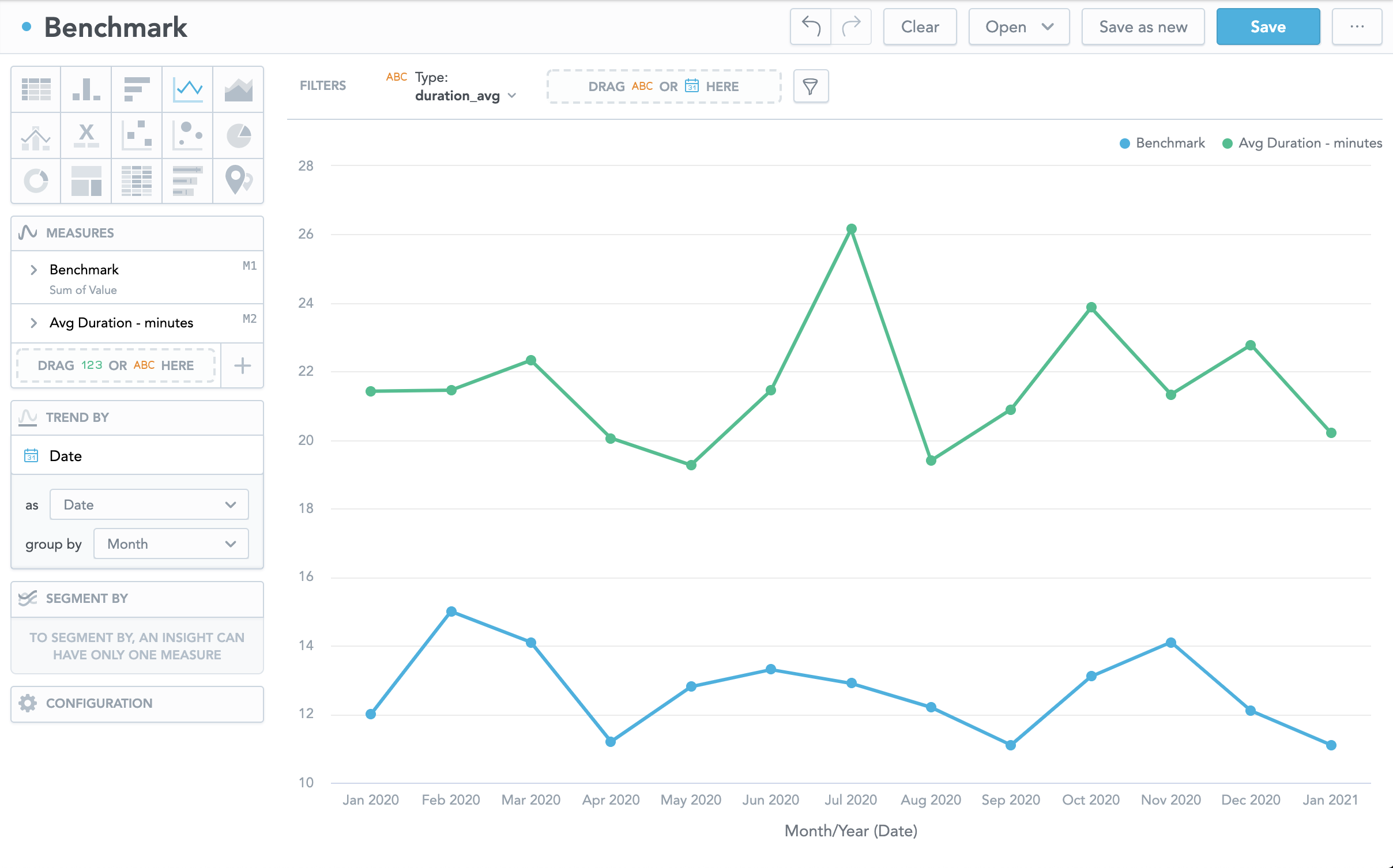
Is this a good approach? Anything you would recommend me?
Thank you.
Robin