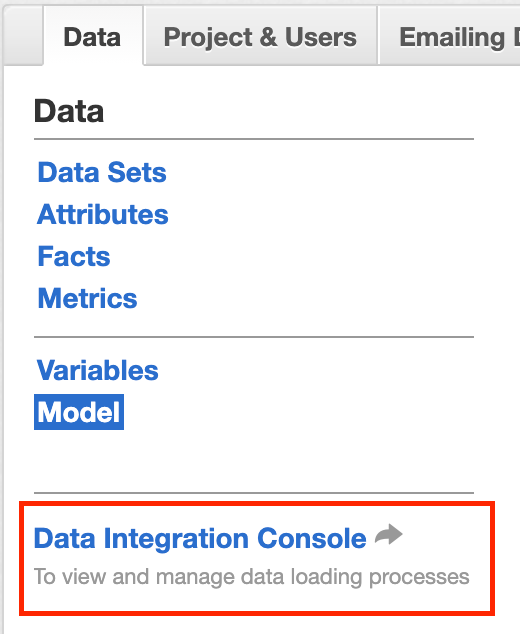
In the January 15th dashboard release, the “Load” button for the Good Data dashboard was changed to “Data” and now there isn’t any way to see my previous uploads from CSV to my dashboard and when I try using the new “Load” function, I get error messages that the data already exists and can’t be updated or replaced.
It looks like I need to rebuild everything, including all my insights, from scratch to make this work again.
Am I the only one here that was uploading from CSV files to the dashboard and having insights attached to those CSV uploads in the past but now have issues with uploading after the January 15th software release?
Thanks,
Seth
Best answer by Andrey
View original