The logs:
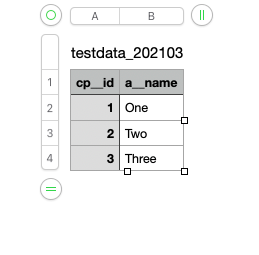
2021-04-02T22:16:13.640+0200 [INFO]: Data distribution worker started2021-04-02T22:16:13.640+0200 [INFO]: Request id: "data_load_uVsUQjWYuv_YTqtNkRU4v:DR7f6UuIF6vgQhKZ:otffmYmekgTqXoYn"2021-04-02T22:16:13.640+0200 [INFO]: Data source: "604fed9d72e8480930e9fe25"2021-04-02T22:16:13.640+0200 [INFO]: Additional parameters: {GDC_DATALOAD_DATASETS=[{"dataset":"dataset.testdata","uploadMode":"FULL"}], PROCESS_ID=1a159b0a-9204-42e1-bb2f-abb07aed7b23}2021-04-02T22:16:13.640+0200 [INFO]: Synchronization mode: selected datasets (default)2021-04-02T22:16:13.943+0200 [INFO]: Synchronized datasets: [dataset.testdata]2021-04-02T22:16:14.057+0200 [INFO]: ====================== Data distribution scope ======================2021-04-02T22:16:14.057+0200 [INFO]: Project="i9kr8f8fd7802orlklcvvhlsr74l057i"; datasets=[{dataset.testdata, loadDataFrom=2021-02-10T02:50:27}]2021-04-02T22:16:14.057+0200 [INFO]: ====================== End of Data distribution scope ======================2021-04-02T22:16:14.057+0200 [INFO]: ====================== Downloading and integrating data ======================2021-04-02T22:16:19.088+0200 [INFO]: ====================== Scanning data files in tfappsheetsbucket/sheets/======================2021-04-02T22:16:19.105+0200 [INFO]: dataset: dataset.testdata; latest Last Load Timestamp:[2021-02-10T02:50:27]; new files: testdata_20210315163115_full.csv .2021-04-02T22:16:19.105+0200 [INFO]: ====================== End of scanning data files ======================2021-04-02T22:16:19.109+0200 [INFO]: ====================== Mapping validation ======================2021-04-02T22:16:19.109+0200 [INFO]: dataset: dataset.testdata, Messages:["The CSV file is missing column(s): cp__id."] 2021-04-02T22:16:19.109+0200 [INFO]: ====================== End of Mapping validation ======================2021-04-02T22:16:19.110+0200 [ERROR]: Fail to load projects "[i9kr8f8fd7802orlklcvvhlsr74l057i]". Reason: Failed mapping validation2021-04-02T22:16:19.111+0200 [INFO]: ====================== End of downloading and integrating data ======================2021-04-02T22:16:19.114+0200 [ERROR]: Data distribution worker failed. Reason: All projects failed to load.
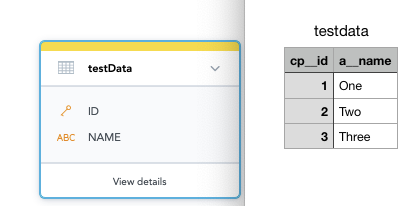
So basically, I have a csv in S3, it has just two columns but I’m getting this error. It doesn’t make sense to me so I figured I’d create a question. I’m just trying to understand how we have to arrange the columns so it loads properly, but yeah this seemed weird so I figured I’d ask here.
Best answer by Daniela
View original