We have noticed that GD.CN initiates 20+ parallel sessions to Vertica, trying to return the entire dataset, while we are not actively running anything. As these sessions trying to return an entire dataset, they are running for hours.
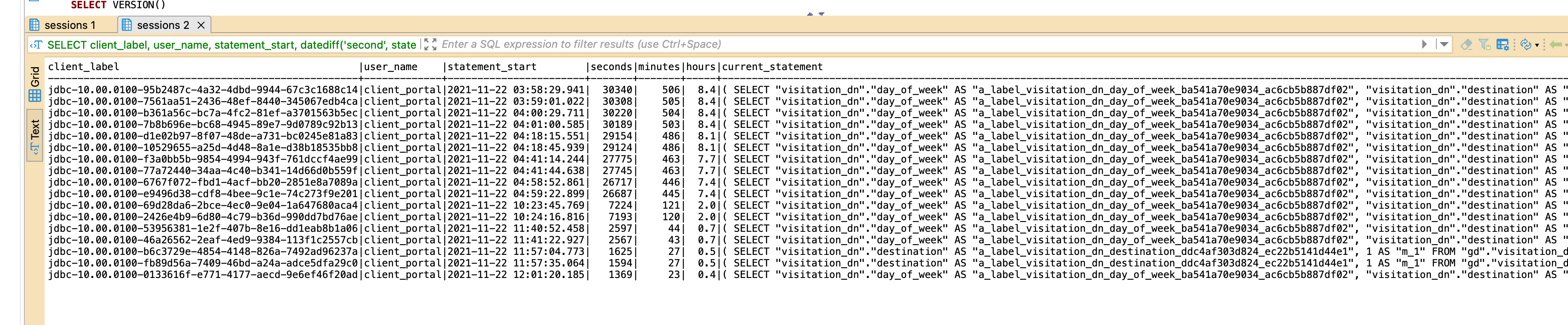
Does anybody nkow why is this happening and how to prevent it?
Best answer by jacek
View original