
Logical Data Model and Performance
This is the final article of the Logical Data Model Series. Today we will focus on impact of the logical data model design to performance.
We are continuing in our series of articles about Logical Data Model in GoodData, in previous articles you’ve learned first what Logical Data Model in GoodData is, then what objects it consist of followed by what are the basic rules for creating a viable model and most recently some pro-tips for great models. If you have missed any of the articles, please read them before continuing with this one.
The Logical Data Model does not only affect which insights you can build, but also their performance. And since cost depends on the data volumes loaded into GoodData as well as the usage, the LDM also affects the cost. So it is good to be smart when designing the data model. Here are some tips to make sure your reports will perform well.
Most of these tips are about creating balance between comfort and performance. In general, it only makes sense to optimize these points when working with millions of records per dataset.
-
Aggregate - do not load more detail than is needed based on the requirements
Pre-Aggregate. If you want to analyze sales by date, product and sales manager, maybe you do not need to upload every single transaction (especially if you have tens of millions of them). Aggregating data by only those dimensions which you care about usually brings data volumes down significantly and therefore boosts performance and reduces costs.
If you do so and aggregate your data, make sure you define the compound primary key correctly (those attributes and references by which you are aggregating the data on the input) and that your facts are additive if possible. This is to be able to calculate your metrics on any aggregation level. For example if you want to calculate the average transaction amount from raw (unaggregated) data you do simple AVG(Transaction Amount). But you can not just pre-aggregate average as a fact to your aggregated dataset (the average would not be additive). Correct way to do it is to aggregate and include total number of transactions as well as total transaction amount. Then you calculate the average transaction amount in any level as SUM(Total Transactions Amount) / SUM(Number of Transactions)
This way you will get exactly the same value of average transaction value, the same reporting possibilities, but much faster and cheaper especially if the number of transactions is very large.
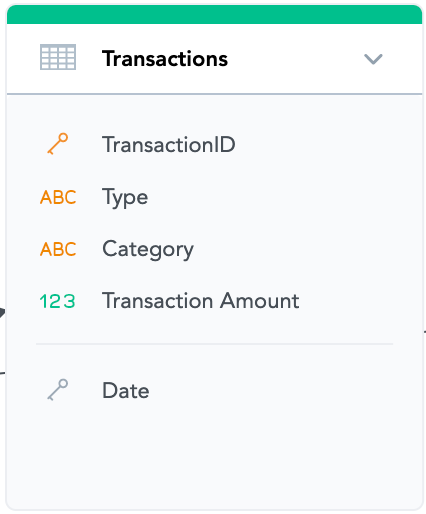
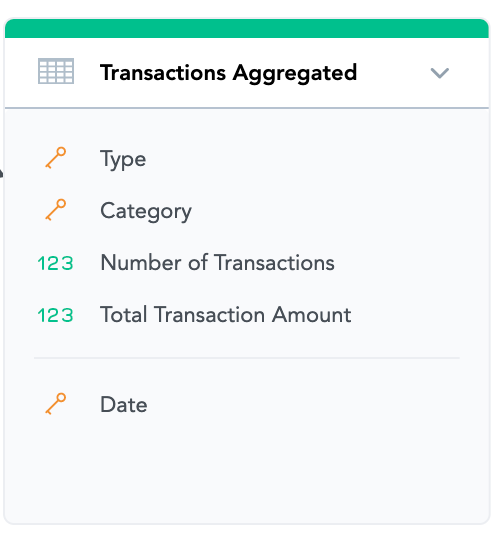
Be careful that some operations are not additive, for example distinct count. If you need those, you might not be able to use aggregation or it will somehow reduce the reporting possibilities. Similar case would be if you need to reference this dataset from another one - that is only possible by unique single-attribute key.
-
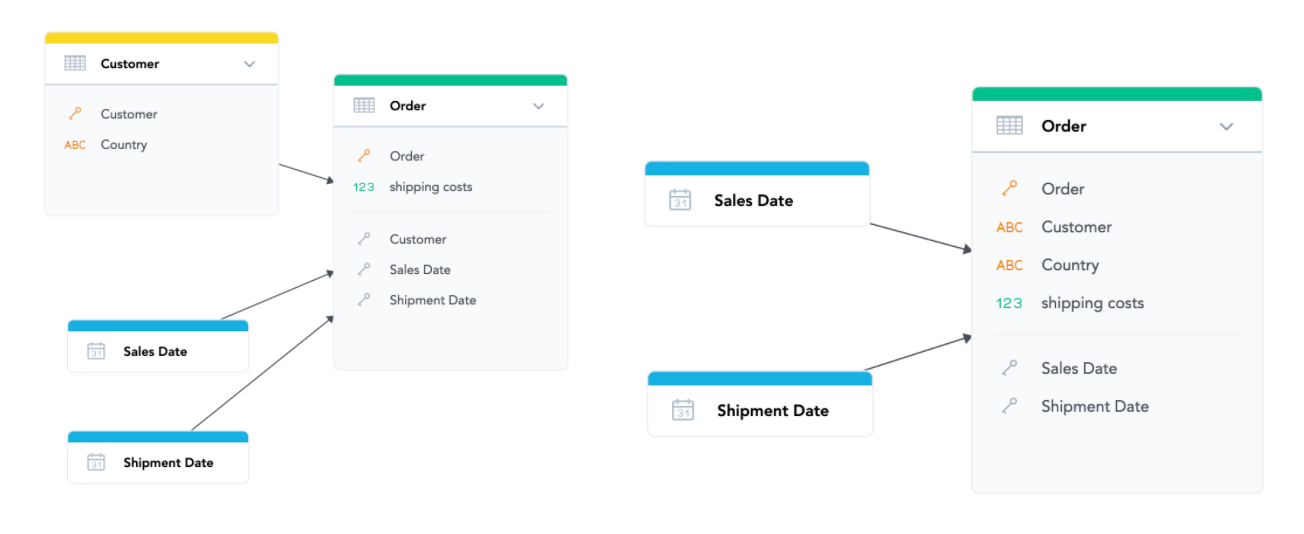
Avoid joins of large datasets if possible
Joining several large tables in a database is a costly operation (both figuratively and literally). If you find that, with your Logical Data Model, you often need to join two or more large datasets (millions of records) and it is causing you performance issues, try to find an alternative method. There are several techniques that might provide this. The easiest would be to merge several large datasets into one. For example, here we have merged “Customer” Dataset together with “Order” dataset. This avoids the join between them, but it comes with a downside - we can no longer report on customers who do not have any orders.
If that is OK for our reporting, we can do this operation. If not, maybe we need to find some other way. These optimizations usually depend on what you and your customers want to see in their reports and dashboards.
-
Avoid high cardinality attributes (not everything needs to have unique ID)
Data people tend to add a unique ID to every single table. It is good practice to do so, but not necessarily in GoodData. GoodData optimizes the physical data model underneath and translates attribute values into internal numerical IDs. This is good for a lot of reasons, but comes with a price. The price being that too many distinct unique values loaded to the workspace can slow down the load.
So if you do not need them for reporting (or unique identification during load), try to avoid loading very high cardinality (tens of millions of records) attributes such as unique IDs if they are not needed. As a reminder - we are speaking about tens of millions of records and more here.
In our sample model, for example, we have an Order Line dataset. Every single record of it is uniquely identified by a combination of the foreign keys - Product and Order. So we do not need to add another unique identifier - Order Line ID. It would not help with the incremental loading (the combination of Product and Order is enough) and we do not need it for reporting. So we avoid loading it into GoodData.
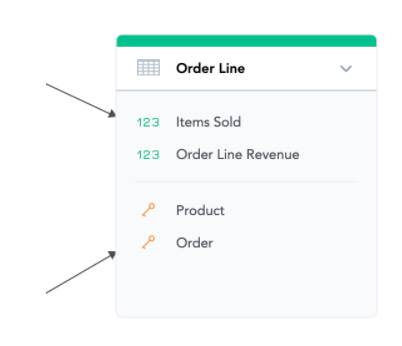
These were three simple rules to keep your data models fast both for data load and for calculation. This is also the end of our series of articles about data modelling in GoodData.
Let us know how you like this series and feel free to post questions if something is not clear to you. For more information and practice about data modelling, please also visit our free courses at GoodData university.