Hi Gooddata,
We would like to tune our GoodData application in our Kubernetes cluster.
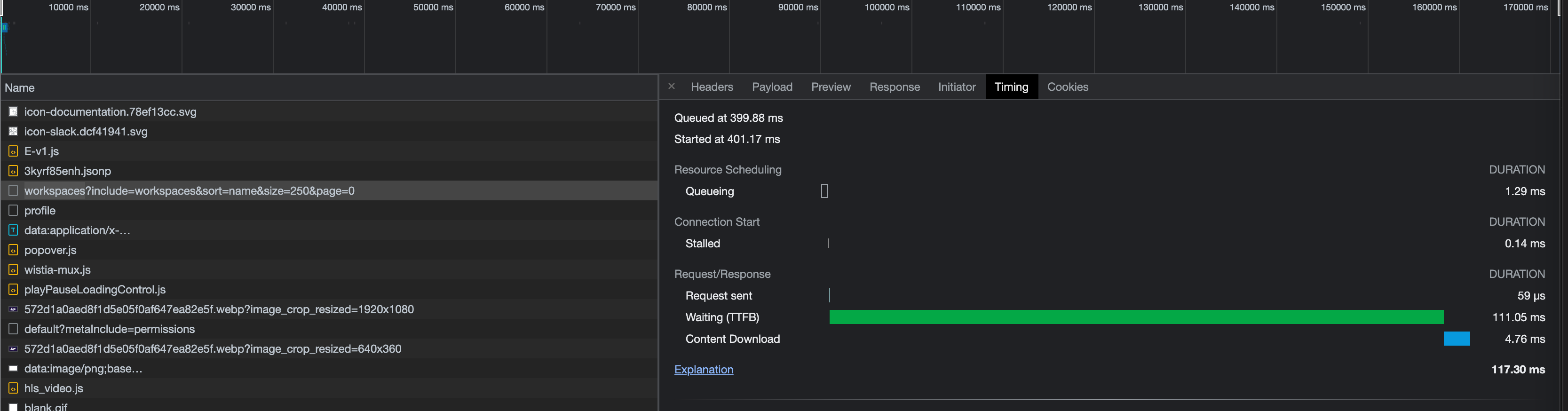
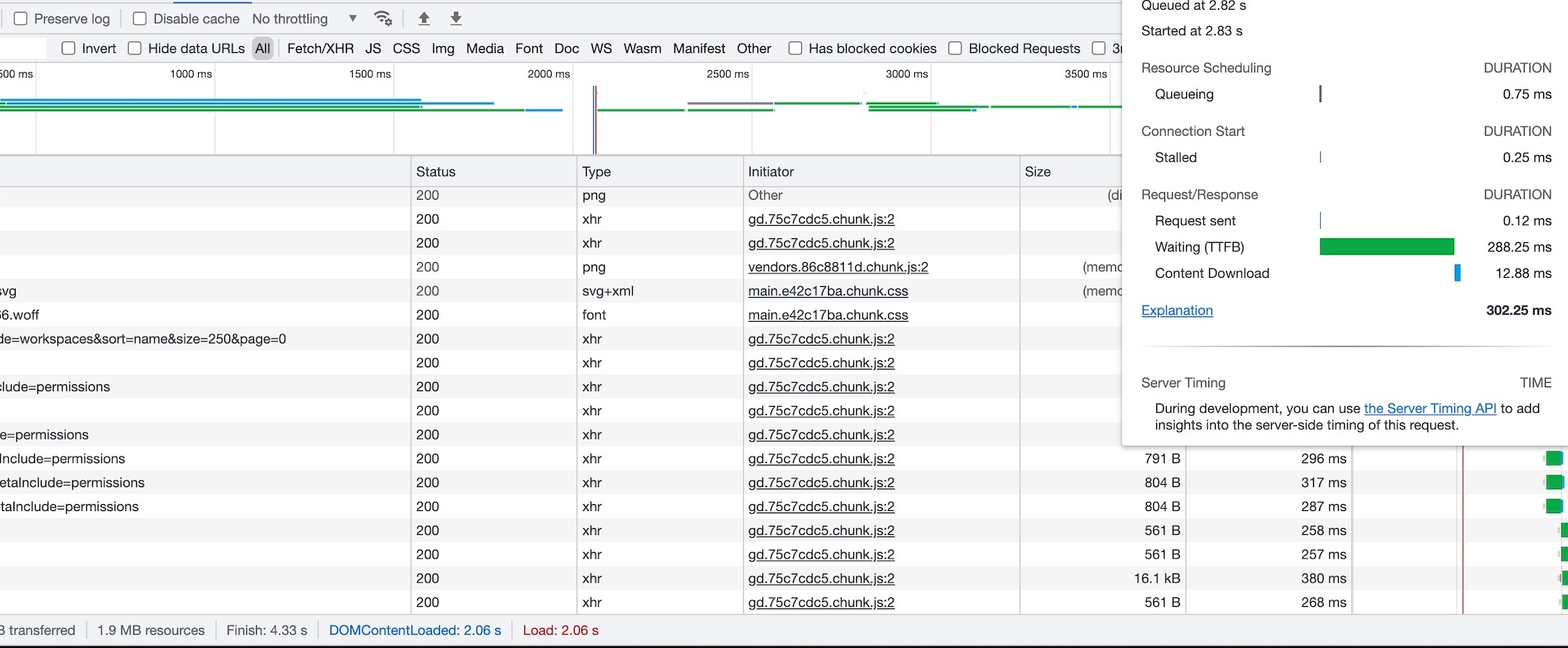
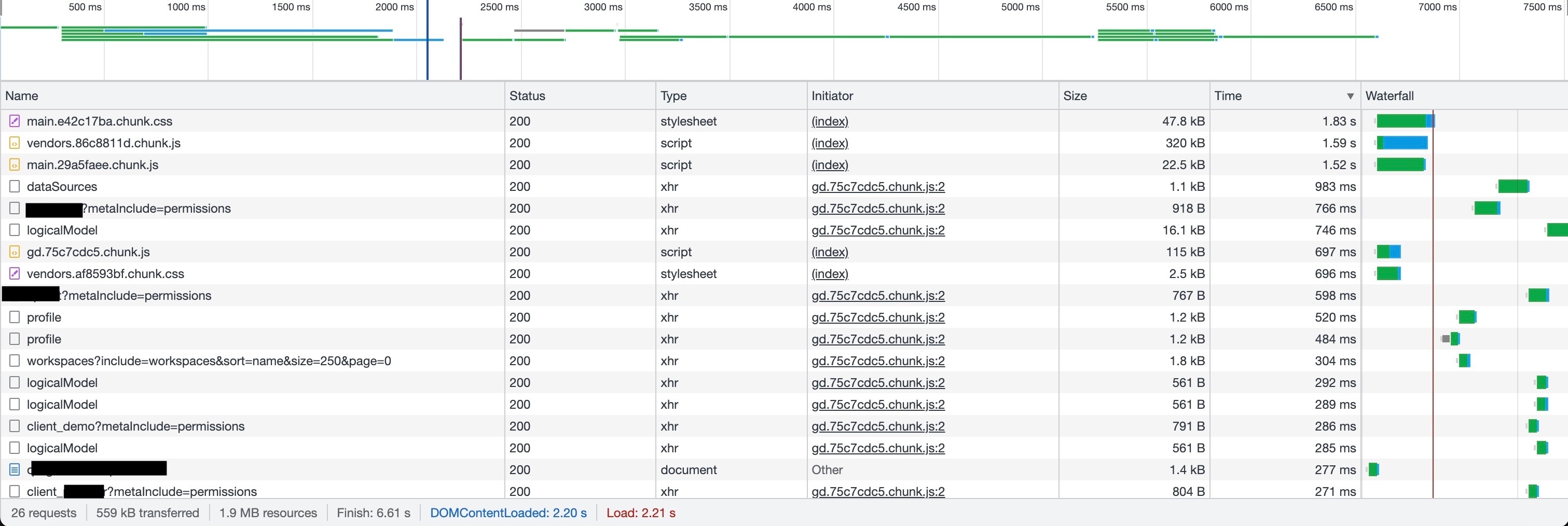
Currently we just use the default values everywhere but it seems a bit slow (all page loadings are slow).
I tried to find topic or details about the performance fine-tune but haven’t found detailed documentation about the options.
My question would be that what types of tune options we have and where can we change?
- java/xmx values
- helm chart options (found some doc)
- recommended node count/aws ec2 instance types
- recommended setup for prod for quick page loading (in terms of gooddata - would not touch the db/dashboards topic, it’s a different stuff) - currently the main page which contains the workspace list loads (4 workspace) around 5-6-7 sec, it should be under 1 sec
Thank you!
Zoltan
Best answer by Robert Moucha
View original