Hello!
I faced the problem of long loading of insights.
Why there are so many requests and they hanging for so long? Are all these requests really needed to display only 8 insights?
When all this is trying to load only within the framework of the personal dashboard dashboard - it seems that you can still live, but when this happens as part of the introduction to another interface - this waterfall of requests interrupts all others and overloads the entire UI system in general.
It can’t be that 3 numbers and 5 charts on 8 insights load for so long, it’s just a return of data, but then you still need to display all this and it also takes time. It can be seen that in total it reaches 100 seconds - this is too much. It could be local server issues, but:
-
Server load (everything is fine, I can show screens that the cores are not loaded at all even with multiple dashboards run).
-
Proxy logic (even by direct link without other libraries or side UI part got long time loading).
-
Drill load (same as server load - nothing hangs).
-
MySQL load (nothing hangs too).
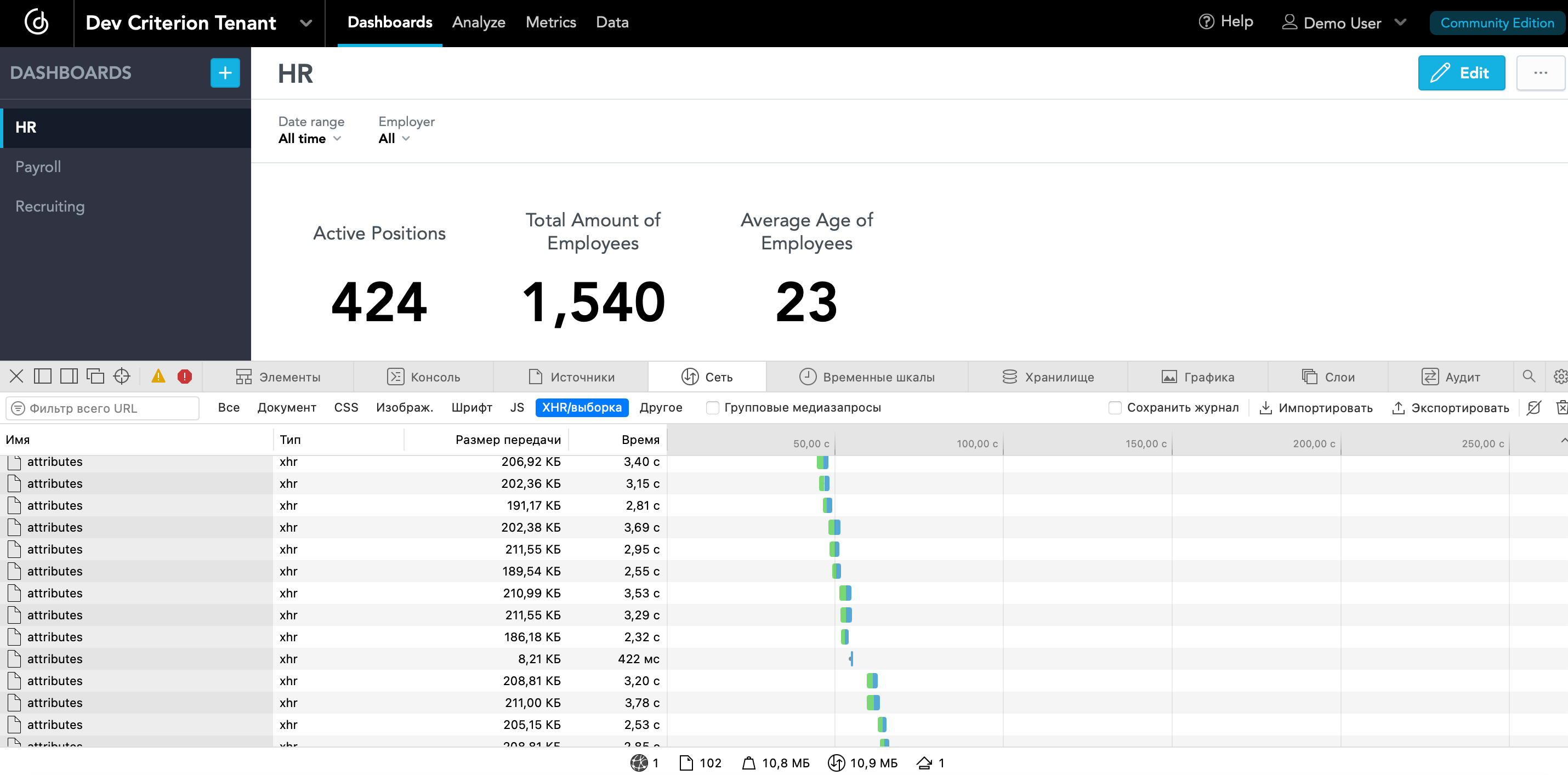
Why, when applying the filter, a large amount of data is loaded again, although in fact they are all already there and have been loaded from the very beginning, why do we need to do this?
I also assume that, for the most part, the data is needed to switch to the insight viewing and editing mode and can be obtained already at the place of the action, and not downloaded immediately.
Conclusion: How to dramatically reduce download time?
I can give personal access in order to investigate it.
Thanks!
Best answer by jacek
View original